


Enterprise SEO once thrived on predictable and overly simplistic mechanics: running SEO audits, building keyword-driven pages, ensuring your information architecture is logical and clean, and creating linkable assets like calculators and guides. But search behavior is changing amongst the younger generations, and simply ranking #1 on Google for “best womens hiking boots” no longer works. What previous generations would use Google for, younger generations are now going to TikTok, YouTube, Reddit, and the most recent addition, generative AI tools like ChatGPT.
While Google Search is 373 times bigger than ChatGPT Search, no one truly knows what the landscape will look like 5, 10, or even 20 years from now. The rise of generative engines (ChatGPT, Perplexity, and Google’s AI Mode) could completely change the daily activities of enterprise SEO consultants like myself, as the rules on how to gain organic visibility are being completely rewritten.
In this new era, success depends less on churning out keyword-driven content and more on shaping how AI systems understand and surface your brand. In this article, we’ll break down the strategies that appear to work in the age of Generative Engine Optimization (GEO), and how enterprise brands can evolve to dominate in the generative engine space.
Disclaimer: The strategies outlined in this article draw from research by companies like Ahrefs, Profound, and others. While I haven’t personally tested all of the recommended strategies, they’re grounded in credible studies and early case data. Consider this a synthesis of what leading voices in the space are seeing; not a guarantee, but an educated guess into which GEO strategies will help you drive results.
How Generative Engines “Think” Compared to Humans
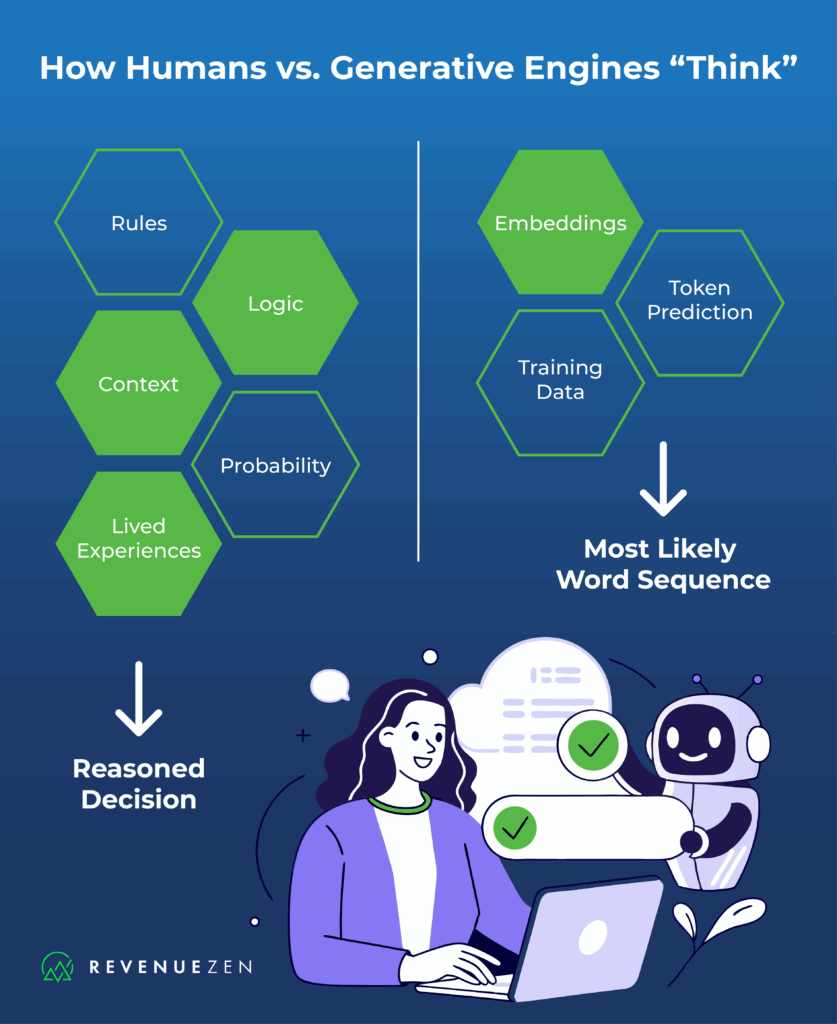
The biggest misconception about generative engines is that they think like humans. Both humans and large language models process information, but the methods are fundamentally different.
Take poker as an example. When you play, your brain isn’t pulling from a static library of past hands you’ve played. You’re using logic and reasoning in real-time:
- You recall the rules of poker, and which hands beat other hands (i.e. a full house beats a straight).
- You calculate odds on the fly.
- For example, there’s 4 spades between your hand and the cards on the flop, meaning you have 9 outs (a 36% chance) of hitting a flush by the river. You’re getting 33% pot odds based on the pot and bet sizing, so you decide to call their post-flop raise.
- You factor in context (an early-position 3-bet from your opponent signals strength, such as AK suited or pocket Jacks).
- You anticipate how the game could change if a certain card comes on the turn (a paired board might mean you could represent a three of a kind or a full house, giving you the opportunity to bluff).
As I mentioned, you’re not replaying old scenarios of hands you’ve played; you’re applying live reads, an understanding of the rules, calculating probabilities, and factoring in player tendencies to make a decision. In other words, you’re using logic and reasoning skills to inform your behavior.
Generative engines like ChatGPT work differently. They don’t reason through the rules of poker. Instead, they predict what words are most likely to come next based on patterns they’ve seen in their training data. That’s why ChatGPT might confidently tell me I’ve hit a flush with only four spades showing (you need 5 cards of the same suit to make a flush). The sequence resembles flush scenarios it’s seen in the past, but without true rule-based reasoning, it can confidently tell you an incorrect answer (which is what we call a ‘hallucination’).
So the main difference here is that humans combine their knowledge with logic and reasoning skills, while generative engines produce plausible continuations of text based on patterns it’s seen without a genuine understanding of what’s going on.
Sam Altman has been clear about the direction they want to take with ChatGPT. According to Sam, the “ideal AI” isn’t a massive encyclopedia of memorized facts; it’s a streamlined reasoning engine that mimics a human’s ability to think, while tapping into external information on a need-be basis. That’s a much more reasonable goal compared to the alternative.
Think about this way—if OpenAI tried to train a new AI model off of the combined knowledge of the entire internet, while still providing it with some level of reasoning skills to determine what’s true and false, the energy costs to build that model would likely reach billions (or even trillions) of dollars, and much of that information would be outdated within days. That approach just isn’t feasible in an ever-evolving world. Unless breakthroughs in quantum computing and nuclear fusion change the equation, the practical path forward is retrieval on demand, with limits on how much information is pulled per query to keep energy costs manageable.
That means OpenAI isn’t trying to replace Google Search; on the contrary, it relies on search and other retrieval systems to provide the raw material it can reason over.
For SEOs, this is good news. Your role will always exist; it will just change over time. The task now is ensuring your brand’s digital footprint (both on-site and off-site) is positioned as a trustworthy source that generative engines will surface and reference when answering user queries that are relevant to your clientele’s business (at every stage of the buying funnel).
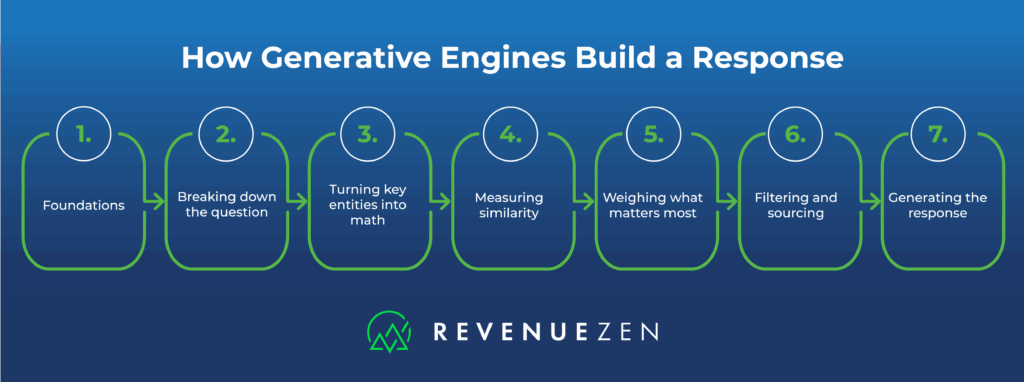
How Generative Engines Synthesize Data
Now that you know how generative engines “think,” let’s look at how they actually build their responses with a real world example. Suppose you ask ChatGPT, “What are the best hiking boots for women in Colorado?” Here’s the process from start to finish.
- Foundations: what the model learned and how: Before any question is asked, the model is trained on very large and diverse datasets that include books, articles, and web pages. Its architecture is a deep layered network with attention and feed-forward layers that capture patterns in language. At training time, it models continuous probability distributions over tokens, which means it learns how likely a token is to appear given the context. This scale and structure enable it to generalize across topics.
- Breaking down the question: The system first breaks your sentence into tokens and uses attention to understand how those tokens relate. It identifies key entities, such as the product (hiking boots), the audience (women), and the location (Colorado). This isn’t old-school grammar parsing, but the model still learns which words and concepts matter and how they connect.
- Turning key entities into math: The model represents meaning as vectors called embeddings. You can think of it as a multi-dimensional map where similar ideas cluster together. Instead of only matching the exact phrase “best hiking boots for women in Colorado,” the system can recognize related concepts like “cold-weather trail shoes” or “mountain footwear for women.”
- Measuring similarity: To find related ideas, retrieval-augmented generation (RAG) systems use external sources (like websites) and compare those on-page embeddings using measures like cosine similarity, which checks whether two vectors point in a similar direction even if the wording differs. For example, “waterproof hiking boots” and “boots that keep your feet dry” are different strings but close in meaning.
- Weighing what matters most: Where and how a term appears influences importance. Transformers encode position directly, so placement shapes meaning. In traditional search, titles and headings tend to get extra weight. With generative engines, surrounding context and emphasis guide what the model highlights. Consider a passage from Clever Hiker:
The Salomon X Ultra 5 Low hiking shoes have a nearly unrivaled balance of durability and low weight – they’re built like a traditional shoe but they fit more like trail runners. These shoes feel much more nimble than others in their category, and they require practically no break-in period. After several hundred miles of testing – including 100 on the rugged Arizona Trail – we’ve found that the traction is well above average on the X Ultras, so they’re great for backpacking or day hikes on challenging terrain.
Notice how “Salomon X Ultra 5” and “durability” appear immediately, reinforcing that durability is a defining feature of that particular shoe.
- Weighing what matters most: Where and how a term appears influences importance. Transformers encode position directly, so placement shapes meaning. In traditional search, titles and headings tend to get extra weight. With generative engines, surrounding context and emphasis guide what the model highlights. Consider a passage from Clever Hiker:
- Filtering and sourcing: Generative models don’t grab everything they’ve ever seen. During training, inaccurate information is cleansed or removed. When retrieval is used on top, filtering is used to keep higher quality sources and reduce obvious mismatches, so a blog about someone’s cat named Boots isn’t confused for a hiking boot review.
- Generating the response: When answering, the model doesn’t look up a single correct sentence; it predicts the next token based on the context and what it learned during training and retrieval, one step at a time until a full answer is formed. This predictive design is why outputs feel fluent and contextually relevant.
Additional Notes on This Process:
- Why it can feel creative, and why it’s not: Outputs can read as creative because the model recombines patterns it’s learned in new contexts. It’s still a pattern recognition system. It doesn’t possess intent, goals, or genuine novelty in the human sense.
- The black box reality: We can describe the architecture and training, but the precise reason a specific token was chosen at a specific step is often hard to trace. That opacity is why these systems are sometimes called black boxes.
- Limitations and risks to keep in view: Bias can surface because training data contains bias. Hallucinations can occur when the model produces confident but incorrect statements. Since training data is based on historical data, the model may lack the most current information unless it uses a retrieval layer.
- Finding the most valuable information: Well-formed answers tend to bring together the brand, the feature, and the audience in ways that reduce effort for the reader. The model doesn’t explicitly use mutual information or simulate information foraging theory, but the result often looks similar. For example, “La Sportiva boots provide excellent ankle support” provides a compact, useful chunk of information.
- The human element: Humans provide the why. Strategy, judgment, values, and context call for expert oversight. The best results come when the model handles pattern recognition and synthesis, and people validate facts, resolve ambiguity, and make decisions.
The Mechanics of Information Retrieval
In Google’s AI Mode, iPullRank’s research shows that a single query is expanded into multiple hidden sub-queries through a process called “query fan-out.” Instead of retrieving full pages, these sub-queries surface the most relevant passages, which are then synthesized into a cohesive answer with citations. ChatGPT and Perplexity appear to use query fan-out as well, though their systems generate far fewer sub-queries and don’t go as deep as Google’s AI Mode.
What the Data is Telling Us
From what I’ve seen, the data is pretty clear; optimizing for generative engines requires a shift in mindset from traditional SEO.
For starters, while ChatGPT has been shown to use Google Search for knowledge retrieval (Source), it overlaps with only about 12% of Google’s cited URLs, so ranking high in Google doesn’t guarantee visibility in ChatGPT results (Source). An Ahrefs analysis revealed that just 14% of the top 50 most-cited websites are shared across ChatGPT, Perplexity, and Google AI Overviews (Source). In other words, each AI system seems to favor different source sets.
With that being said, a study of 500 queries (which is a very small sample size and should be taken with a grain of salt) found that 87% of ChatGPT’s citations aligned with Bing’s top 20 results (Source), meaning that ranking well for a given keyword target in Bing could potentially translate into being used as a source for that same query in ChatGPT. This is the closest signal I’ve seen to confirming the claim that traditional SEO leads to positive GEO performance.
In regards to preferred sources, Profound’s data shows that ChatGPT heavily favors Wikipedia at 48%, while Perplexity leans on Reddit at 47%, and Google AI Overviews pulls from a mix of Reddit, YouTube, Quora, and LinkedIn (Source).
This reinforces the need for platform-specific strategies instead of assuming visibility in one system guarantees presence in another. And while that’s the ideal scenario, that can be very resource intensive, which is one of the reasons why Profound recommends pursuing citation overlap across sources that multiple AI platforms favor. Brands that show up on these overlap domains see far greater visibility across all major AI search engines (Source).
Across the board, comprehensive, clearly structured content outperforms traditional SEO assets like backlinks. A Growth Memo study found that generative AI tools are far more likely to cite content that’s detailed, well organized, and easy to understand than pages with high authority or strong link profiles (Source). But on the other hand, Ahrefs’ data showed that domain-level link metrics (like Ahrefs Rank, Domain Rating, number of referring domains, and total backlinks) have very weak or no correlation with how often domains are mentioned in AI search systems, while brand-specific signals (especially unlinked mentions, anchor mentions, and branded search volume) show much stronger correlation with visibility in AI Overviews (Source).
In fact, branded web mentions had the highest correlation to appearing in Google AI Overviews at 0.66, with far weaker correlations for ChatGPT at 0.15 and Perplexity at 0.30 (Source).
From a demand perspective, generative engine use is only increasing. Ahrefs reports that AI traffic to websites has increased 9.7x (across a dataset of 81,947 sites) in the past year (Source). At the same time, Ahrefs reports that AI-driven traffic now accounts for about 0.5% of their own total web traffic (for ahrefs.com), but that small slice drives over 12% of their signups and converts at 23 times the rate of traditional organic visitors (Source).
As AI-generated search continues to scale, crawler logs show AI bots now make up nearly 19% of all web crawler activity, putting them second only to search engine crawlers (Source).
Profound’s landmark study highlights a sharp difference between how people use Google and ChatGPT (Source). On Google, queries are mostly informational (52.7%), navigational (32.2%), and commercial (14.5%), with very few transactional searches (0.6%). ChatGPT shows a different pattern: generative (37.5%) is the largest category, followed by informational (32.7%), no clear intent (12.1%), commercial (9.5%), transactional (6.1%), and navigational (2.1%). This indicates that while commercial purposes are somewhat even across both platforms (in terms of percentages), there is a notable increase in transactional requests and a strong emphasis on generative use cases (where users want the tool to create, summarize, or complete tasks rather than just provide information).
This reinforces Ahrefs’ findings for their own site in how transformational ChatGPT can be in driving purchase decisions, even if its user base is much smaller than Google’s.
All of this leads to a clear takeaway: success in generative search largely won’t come from the old SEO playbook. The landscape is fragmented, with each platform favoring different signals. The problem is that working in a fragmented way drains efficiency and forces you to chase too many tactics at once. That’s why, in this next section, my goal is to distill these strategies into a unified framework; one you can apply broadly when building client roadmaps (without being locked into any single AI platform).
5 Key Strategies for Generative Engine Optimization
So with all of this data in mind, let’s dive into how you’d actually do Generative Engine Optimization for your clientele.
1. Craft Content Around Entities, Not Just Keywords
One of the biggest shifts in the age of generative search is that strategists will need to part ways with SEO tools that no longer provide the depth or relevance we now require for content creation. I won’t call any companies out, but the way many of those tools work is by analyzing the top 30 search results on Google and telling you which terms to include in your content based on the frequency of those words being used on the top ranking pages. That approach may have made some sense when Latent Semantic Indexing (LSI) was trending in the SEO community (even though it was a misguided concept to begin with), but generative engines process language using embeddings and entity recognition, not in exact phrases.
In the earlier hiking boots example, the model didn’t just do a keyword search for the phrase “best hiking boots for women in Colorado” across its index. It broke that query into key entities (hiking boots, women, and Colorado) and formed an embedding. Then it searched for resources related to that embedding, even if it used entirely different words like “alpine trail footwear” or “cold-weather shoes.”
That’s why optimizing around the frequency of words used in top ranking articles misses the mark. These generative engines don’t care about the repetition of words and they don’t identify the same citations as useful resources; they care about depth and clarity around the right core concepts.
To overcome the limitations of most SEO tools, try using this straightforward approach instead:
- Start with a generative search: Use ChatGPT with browsing enabled, Perplexity.ai, Bing Copilot, or Google’s AI Mode (whichever model you’re optimizing for). Enter your topic and study the response. Which brands are mentioned? What features or phrases come up repeatedly? Are there patterns in the language or structure?
- Collect the cited sources. Most generative tools include footnotes or links. Save those URLs and keep the AI-generated response as well.
- Run the content of those pages through an entity extraction tool. These tools scan the content and pull out the most important concepts, such as products, brands, technical specs, and locations. Tools like Google Cloud Natural Language, IBM Watson NLU, Diffbot, or SpaCy can help. Some are easy to use, while others need a bit of setup. You could also build your own in n8n by plugging the query into the latest chat model, parsing the citations, scraping the body content for those citations, and running them through the Google Cloud Natural Language API.
- Use those entities to shape your content outline. Once you know what concepts are driving relevance, write content that builds around them. For example, if GORE-TEX, zero-drop design, or Rocky Mountain hiking conditions appear to be central themes, make sure your content speaks clearly and in-depth about those ideas. Maybe you’d have an entire section dedicated to what the Rocky Mountain hiking conditions are in different seasons.
- Use natural phrasing, include comparisons, highlight features, and support your writing with examples. You’re not stuffing in related words; you’re intentionally building content from the ground up around core concepts.
This approach helps close the gap between how users search and how machines interpret content. Instead of writing for keyword rankings, you’re writing to be within striking distance of the embedding. If your brand becomes associated with the right entities, it can show up in synthesized answers (even without being the top-ranking source).
2. Write Semantically Rich, Machine-Friendly Content
To get picked up by generative engines, your content needs to do two things at once: show real subject-matter depth and be packaged in a way that’s easy for models to scan, summarize, and cite. Depth without structure gets buried, and structure without depth gets ignored. The winning formula is both.
- Add depth and context: Clarity is critical for RAG systems. Algorithms can’t parse or surface what they don’t understand, and ambiguity can make your content invisible. Write as if you’re teaching someone who actually wants to learn. Break down complex ideas into clear explanations, moving beyond surface-level descriptions. If you’re covering a product, explain not just what it does, but how it works, when to use it, and what makes it different from alternatives. Go beyond specs; include performance notes, tradeoffs, and edge cases.
- Use entities (people, places, organizations, products, events, and concepts) as the building blocks of the page. Strong content clearly signals the main entity and its related context. Take Salesforce as an example. To make content unambiguous, you wouldn’t just mention “Salesforce CRM.” You’d strengthen the context by including related entities like cloud computing, enterprise software, customer data, integrations, automation, and competitors in the CRM market. The richer the entity co-occurrence, the clearer the meaning.
- Offer unique, data-driven insights to boost authoritativeness (i.e. using proprietary statistics or analysis rather than generic statements).
- Layer in context with comparisons, analogies, and use-case examples that tie features to real-world decisions. Instead of listing benefits, frame them in situations people care about. And don’t stop at what something is; explain the why and when. Why would someone choose this option over another? When does it shine, and when might it fall short? These are the insights generative engines prioritize when selecting citations.
- Make it scannable and machine-friendly: Generative engines don’t process your content like a human. They’re parsing for structure, clarity, and semantic signals. To help them (and your readers):
- Use short, focused paragraphs. Each should communicate a single idea. Avoid long blocks of text.
- Write descriptive subheadings. Instead of vague labels like “Overview,” use precise ones such as “Top Hiking Boots for Wet Trails in Colorado.” This gives engines strong signals about the section’s purpose.
- Organize details into lists or tables. If you’re comparing products, steps, or features, structure them so information can be extracted at a glance. For example:
| Boot Name | Best For | Standout Feature |
| Salomon X Ultra 5 | Technical terrain | Lightweight and waterproof |
| Lowa Renegade | Long-distance hikes | High ankle support |
| Altra Lone Peak | Natural foot movement | Zero-drop, wide toe box |
- Build comparison pages: AI appears to love side-by-side evaluations for middle and bottom-of-funnel queries. Create a mix of formats: your brand vs competitors, multi-way comparisons, ICP-specific matchups (e.g. “Hubspot vs Salesforce for Enterprise Brands”), feature-driven comparisons, and even competitor-vs-competitor pages. These align with how generative engines refine queries and boost your chances of being cited.
- Write with clarity and consistency: Use plain, confident language at about an 8th–10th grade reading level unless technical detail is essential. Avoid keyword stuffing, filler, or robotic phrasing. The more your content reads like a knowledgeable person explaining something clearly, the easier it is for engines to interpret and trust.
Consistency also matters. If you’re producing a series of similar guides, stick to a repeatable format. A predictable structure improves both human readability and machine synthesis, increasing the odds your content is cited accurately.
When you combine depth of insight with clean, scannable presentation, you make your content more useful to people and more accessible to generative engines. That balance is what gets your brand surfaced, summarized, and trusted in AI-driven results.
3. Maximize Visibility on Key Off-Site Sources
As search behavior splinters across platforms like ChatGPT, Perplexity, and Google’s AI Mode, the sources feeding these generative models are fragmenting as well. Reddit threads, YouTube product reviews, product pages, Forbes articles, help desk docs, and countless others all shape the answers these systems produce. If your brand only exists on your own site, its visibility is capped. The more signals LLMs encounter across the open web for a particular embedding, the more likely your brand is to be surfaced in their responses.
Here’s how to broaden your surface area:
- Publish across multiple social and content platforms: Extend your content beyond your website. That could mean writing an article for your blog, creating an educational video based on your article for YouTube, answering related questions on Reddit, and republishing insights on LinkedIn, Medium, or industry forums (just be sure to tailor the content; rewrite it to match each platform’s audience, tone, and format expectations rather than reposting it word for word). Each platform gives generative engines another opportunity to encounter and trust your brand.
- If you’re optimizing for both AI and traditional search, try this strategy: plug reddit.com into Ahrefs’ Site Explorer, click on “Top pages,” and filter by a relevant keyword (such as “best hiking shoes for women”). This will show you which Reddit threads are already ranking well in Google. You can then leave valuable comments on those posts as a brand representative, offering useful advice and deeper context.
- Some marketers use grey-hat tactics where one account asks a keyword-stuffed question and another answers it to manipulate rankings on Google’s “Discussions and forums” feature. While this may work temporarily, Reddit and Google are likely to improve their detection systems over time by analyzing account age, karma, posting patterns, and other behavioral signals. Brands focused on long-term visibility should lean toward authentic, value-based participation instead. Community moderators can also flag and ban accounts if posts or comments feel spammy, cutting off your brand’s access to the very audience you’re trying to reach.
- Contribute to trusted third-party publications: Getting your brand mentioned in high-authority outlets helps both with traditional SEO and with AI visibility. Pitch guest posts, contribute expert quotes, or take part in interviews on sites your target audience already reads. Listicles (like “Top 10 Best Customer Relationship Management Systems for Enterprise Brands”) are especially common among the sources ChatGPT pulls from for middle and bottom-of-funnel queries. Plug in your target query into ChatGPT or Perplexity, look at which citations they’re using, and reverse engineer those content formats (and distribute them to authoritative, often-cited websites).
- If possible, aim to appear on the top domains in the Profound study for the generative engine you’re targeting. If you’re aiming to be the featured solution for ‘best CRM software for enterprise brands’ on ChatGPT, ideally you’d:
- Be the featured brand on listicles for that search term across Forbes, Business Insider, NY Post, TechRadar, etc.
- Have high-quality reviews of your software on G2
- Be mentioned in relevant subreddits as the best CRM software for enterprise use cases.
- Have a Wikipedia page that reaffirms you’re best-in-class.
- Etc.
- Recent research on Perplexity uncovered that its ranking system isn’t purely algorithmic. Certain “authoritative domains” like Amazon, GitHub, Coursera, LinkedIn, Slack, and Figma receive manual boosts inside the model. If your content appears on or is associated with these sites, it automatically gains more weight in Perplexity’s results.
- If possible, aim to appear on the top domains in the Profound study for the generative engine you’re targeting. If you’re aiming to be the featured solution for ‘best CRM software for enterprise brands’ on ChatGPT, ideally you’d:
- Encourage user-generated content and detailed reviews: Ask customers to leave reviews that clearly mention your product name or brand. Platforms like Google, Yelp, Amazon, TripAdvisor, and Facebook often rank high in trust and visibility, and their content is frequently pulled into AI-generated answers. Even reviews on your own product pages could help if structured well and marked up properly.
- I haven’t seen any clear evidence that AI tools actively use schema/structured data yet (excluding Google), but it’s likely coming. At a minimum, it’s worth standardizing your customer review process now to future-proof your content. Include specific questions and display that information directly in each review to make it readable for AI, such as:
- 5-star rating with a recommendation tag (e.g. “Yes, I would recommend this product”)
- Age, height, and weight of the reviewer
- Overall quality rating of the materials used
- Fit or sizing feedback
- Ease of use or setup
- Product commentary
- Etc.
- I haven’t seen any clear evidence that AI tools actively use schema/structured data yet (excluding Google), but it’s likely coming. At a minimum, it’s worth standardizing your customer review process now to future-proof your content. Include specific questions and display that information directly in each review to make it readable for AI, such as:
These details not only improve credibility and trust with human readers, but also give generative models clearer context when they begin to parse the review. And by guiding reviewers on exactly what you’d like them to talk about in the review, you increase the likelihood of high-quality passages that give incredible context to the LLM.
The bottom-line here is that the more high-quality sources your brand appears in, the more opportunities you create to be discovered, retrieved, and cited in generative search results. You’re not just optimizing a single piece of content; you’re building a network of mentions across the platforms that generative engines scan for answers. Each additional mention improves your brand’s visibility and credibility in this new search ecosystem.
4. Build Pages That Generative Models Can Trust & Easily Retrieve
If a generative engine is pulling information from live web sources, your goal is to become the page it finds, understands, and trusts enough to cite. This isn’t just about ranking high on Bing for a given keyword target; it’s about being clear, focused, and relevant enough to be selected in real time as part of a synthesized answer.
Here’s how to build a content strategy that supports retrieval:
- Give each page a clear focus: Avoid broad, unfocused content. Instead, build each page around one core topic or question. For example, a guide titled “How to Choose the Best Trail Running Shoes for Rocky Terrain” should stay tightly focused on that specific scenario. Then, create supporting articles that explore related topics in more detail.
- Keep your content fresh: Pages that are regularly updated have a better chance of being retrieved, especially on Perplexity (Source). Revisit older content and refresh it with new product recommendations, updated statistics, or revised insights. Even small changes help show that your content is active and maintained, which can increase its chances of being pulled into real-time answers.
- Make the technical side clean and simple: Use readable URLs, fast-loading pages, and a straightforward layout. Avoid heavy client-side rendering or interactive JavaScript that can block key page elements. For example, many developers display large sets of product reviews behind JS-driven pagination or user-activated buttons that generative engines can’t access. Generative models are more likely to retrieve and quote content that’s easy to parse and clearly presented, so keep formatting consistent and avoid clutter that might distract from the main point of the page. Also, make sure the raw and rendered code for the page is logically structured and easily parsable.
- Ensure Google / Bing / Perplexity are crawling / indexing your site: It doesn’t matter how strong your content is if generative engines can’t access it. Start with the basics: confirm your XML sitemaps are submitted in Google Search Console and Bing Webmaster Tools, link to your XML sitemaps in your robots.txt file, and check crawl stats to verify bots are hitting the pages you want surfaced. Use “site:” searches and conduct a log-file analysis to catch indexing gaps. Blocked resources in robots.txt, overly aggressive use of meta noindex, or JavaScript-heavy content that doesn’t render cleanly can all prevent crawlers from seeing what matters.
By tightening your topical focus, keeping your content current, cleaning up your site’s technical structure, and ensuring your raw/rendered code is easily parsable, you improve your chances of being cited the most in the generative answer.
5. Track Visibility and Measure Your Generative Footprint
In traditional SEO, visibility was straightforward to measure: keyword rankings, non-branded clicks, organic revenue, and conversions. In GEO, it’s far murkier. You don’t know every prompt that surfaces your brand, how your visibility stacks up against competitors, or which prompts actually lead to sales. That uncertainty means measurement itself has to evolve.
Track Retrieval, Mentions, & Referrals
Instead of “How well am I ranking for XYZ keyword?” we must now ask “How often is my brand being retrieved, cited, and surfaced by generative engines?” Tools like Profound, Ahrefs Brand Radar, and custom dashboards help you monitor:
- Citations / mentions: Are you being mentioned on ChatGPT, Perplexity, Google’s AI Mode, etc.?
- Overlap across engines: Which queries and platforms are you dominating, and which ones are you falling short on relative to the competition?
- Context of mention: Did the mention present your brand in a positive, neutral, or negative light?
- Competitor share of voice: Are you being mentioned more often than your competitors, and are you being featured more prominently?
Although these tracking tools rely on synthetic queries (usually drawn from high-volume SEO keywords) and it’s difficult to gauge their true search demand in AI platforms (since AI queries tend to be longer and more nuanced), synthetic queries remain a useful proxy. It’s logical to assume that a theme like ‘best crm software,’ which receives 2,300 monthly searches on Google, is also being searched for on ChatGPT and Perplexity in some capacity. It’s up to you as the SEO Strategist to identify those key themes, and use tools like Profound to track your visibility for those themes (and benchmark that visibility against competitors).
Setup New Reporting
Because referral traffic is usually somewhat messy, I recommend setting up a custom segment for utm_source=chatgpt.com, utm_source=Perplexity, or other unique URL parameters in GA4. Once you’ve done this, build out a custom Looker Studio report that highlights sessions, new users, conversions, etc. for these different sources.
Once that’s complete, layer in a server log analysis every month (or quarter) to see how often AI bots like ChatGPT-User, PerplexityBot, or ClaudeBot are crawling your site. Note which pages they’re hitting often, and reverse engineer what they’re looking for to find ideas on how to improve that content, or new pieces of content you should create.
Build Multi-Layered Measurement
The iPullRank framework suggests breaking measurement into three tiers:
- Input Metrics: Passage-level relevance, AI bot crawl activity, and synthetic query rankings.
- Channel Metrics: Share of voice, citation frequency, and citation overlap across engines.
- Performance Metrics: Conversions, pipeline influence, and revenue attribution.
This layered view shifts the focus from “where do I rank” to “how is generative visibility driving business?”
Turn Insights Into Strategy
Tracking doesn’t just tell you where you currently show up; it tells you where you should show up. Common insights include:
- Hallucinated URLs: Models think you should have a page on a particular topic. Redirect those URLs to relevant pages for now, but also treat the phantom page as demand intel and create a page around that intent.
- Entity gaps: If you’re not being cited alongside core competitors, you may need more entity-rich content.
- Channel bias: If Perplexity cites Reddit more often while ChatGPT leans on Wikipedia, invest in PR and content distribution to cover both (or prioritize the one with the greater potential return on investment).
Conclusion
Generative engines are reshaping the rules of organic visibility. Ranking first on Google is no longer the only goal; we must now turn our brands into a trusted signal within the ecosystems that fuel AI answers. That requires moving from keyword-driven tactics to entity optimization, producing semantically rich content that can be scanned and cited, expanding our presence across the platforms AI systems pull from, and structuring our sites for real-time retrieval.
The evidence is clear: authority in generative search isn’t built on backlinks; it’s built on relevance. “Relevance engineering” involves showing up across key sources, publishing content that teaches and contextualizes, and ensuring everything you produce is accessible and readable by AI crawlers. Doing great SEO won’t necessarily result in generative engine visibility; it requires new tactics that lean into how these engines source information. The brands that adapt early with sharp measurement, strong content, and a focused Digital PR strategy will be the ones that lead as AI-driven search becomes the primary way people discover information.